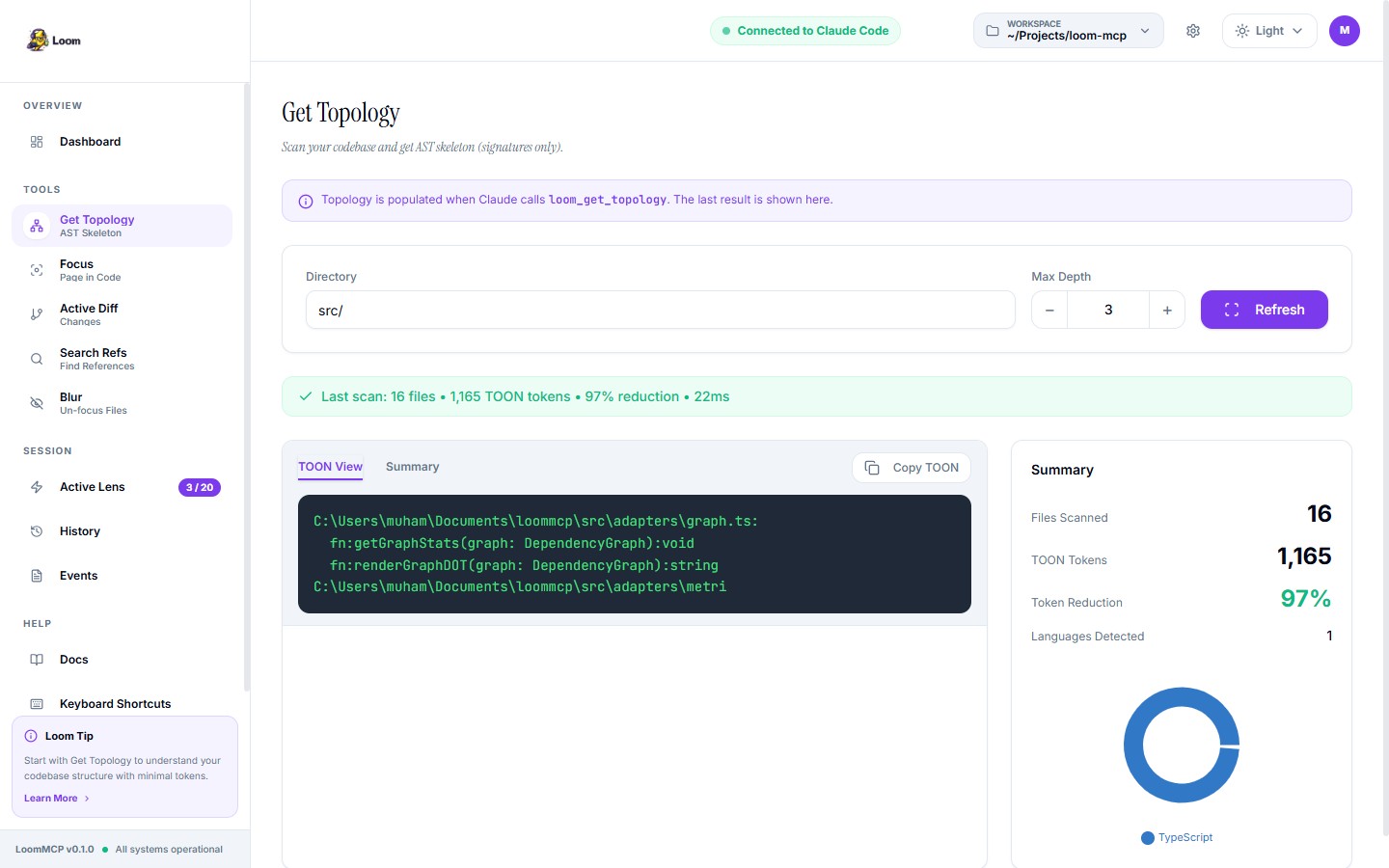
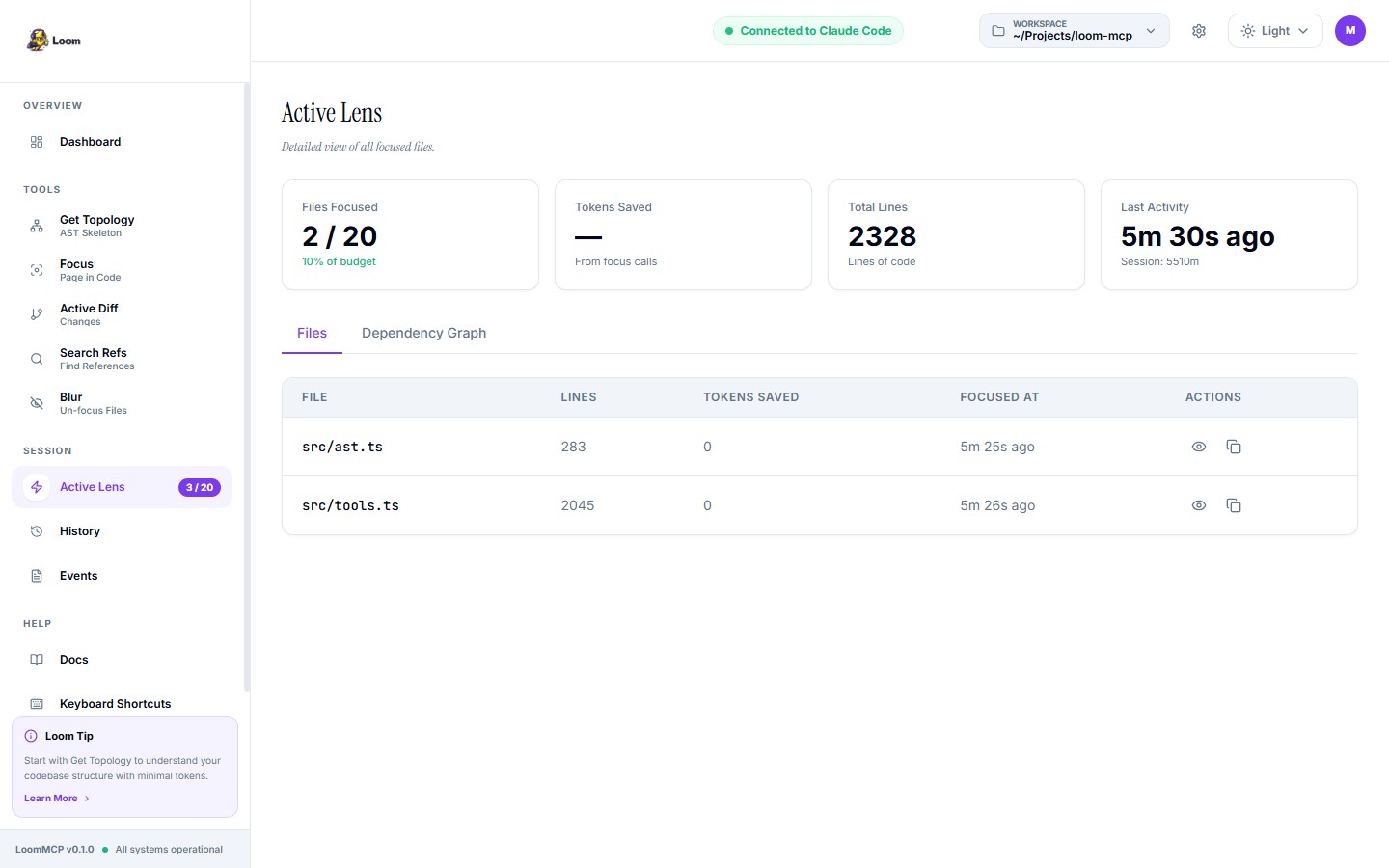
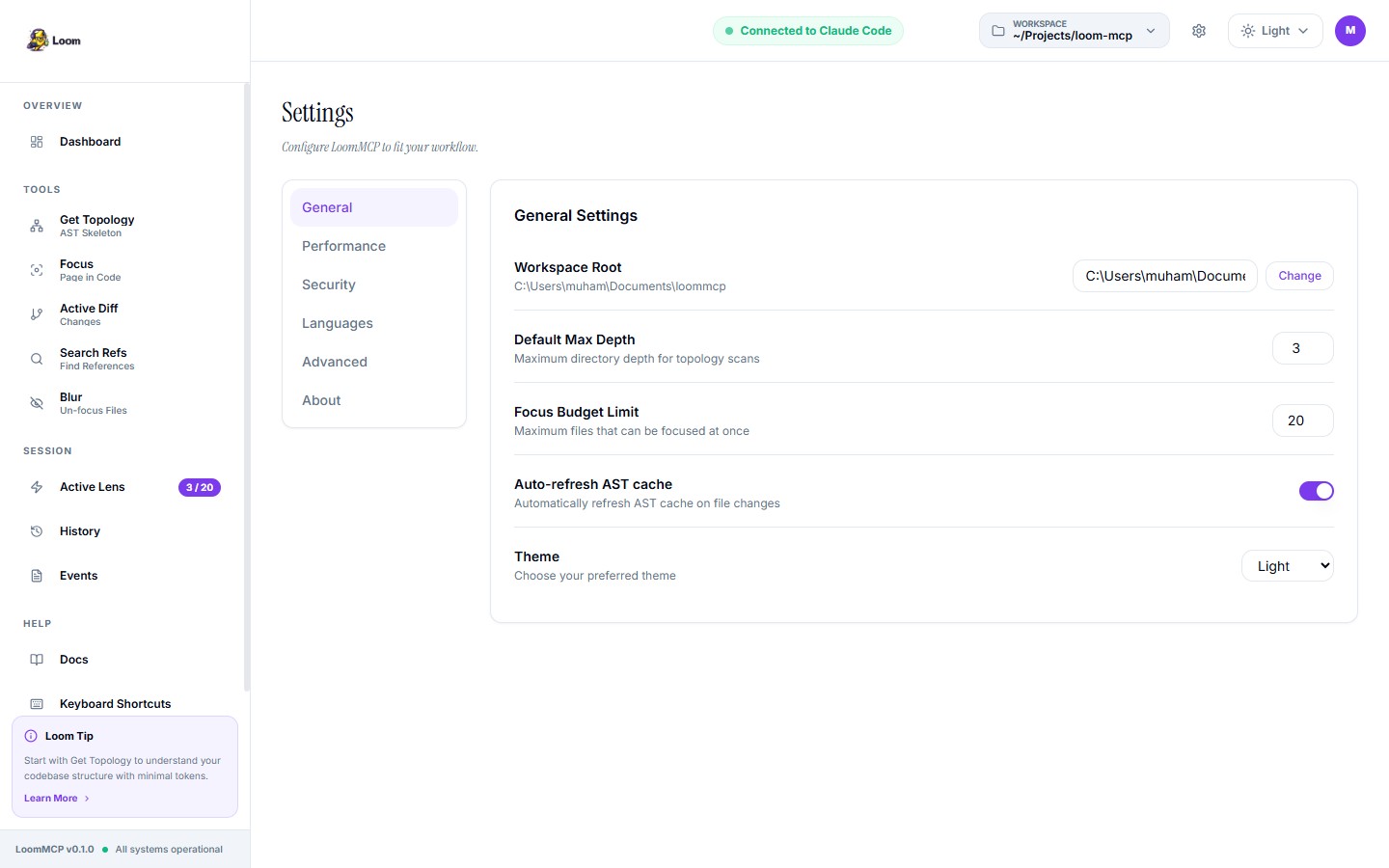
Traditional AI Context
Reads entire files. Wastes tokens.
- auth.ts
- middleware.ts
- db.ts
- utils.ts
- types.ts
- +200 more files
1 import jwt from "jsonwebtoken"
2 import { User } from "./types"
3
4 export async function loginUser(){
5 const user = await db.find(...)
6 const valid = await bcrypt(...)
7 if(!valid) throw new Error(...)
8 const token = jwt.sign(...)
9 return user
10 }
...